Nama Anggota Kelompok :
1. Kelvin Bun - (55414804) - Pengantar Komputasi GRID
2. Sarah Ramadhanty
Putri (5A414038) - Virtualisasi
3. Rastiko Kuncorojati - (58414937) - Map Reduce dan NoSQL (Not
Only SQL)
4. Hendika Julbahri Arbansya Surbakti - (54414736) - NoSQL Database
Kelas : 4IA20
Mata Kuliah : Pengantar
Komputasi Modern
Dosen : Lely Prananingrum
A. Pengertian Grid Computing
Komputasi
Grid adalah penggunaan sumber daya yang melibatkan banyak komputer yang
terdistribusi dan terpisah secara geografis untuk memecahkan persoalan
komputasi dalam skala besar. Grid computing merupakan cabang dari distributed
computing.Grid komputer memiliki perbedaan yang lebih menonjol dan di terapakan
pada sisi infrastruktur dari penyelesaian suatu proses. Grid computing adalah
suatu bentuk cluster (gabungan) komputer-komputer yang cenderung tak terikat
batasan geografi. Di sisi lain, cluster selalu diimplementasikan dalam satu
tempat dengan menggabungkan banyak komputer lewat jaringan.
Grid
Computing erat kaitannya dengan metode komputasi paralel. Metode ini dapat
membagi kerja komputer menjadi beberapa bagian sehingga, tidak memberatkan
kerja komputer itu sendiri dan mempercepat kerja komputer.
Grid
Computing memanfaatkan kekuatan pengolahan berbagai unit komputer, dan
menggunakan kekuatan proses untuk menghitung satu pekerjaan. Pekerjaan itu
sendiri dikontrol oleh satu komputer utama, dan dipecah menjadi beberapa tugas
yang dapat dilaksanakan secara bersamaan pada komputer yang berbeda.
Tugas-tugas ini tidak perlu saling eksklusif, sebagai tugas lengkap pada
berbagai unit komputasi, hasil dikirim kembali ke unit pengendali, yang
kemudian membentuk keluaran kohesif. Salah satu komponen yang
terpenting juga dalam grid computing adalah konektifitas atau jaringan.
B. Konsep Grid Computing
Beberapa
konsep dasar dari grid computing :
1. Sumber daya dikelola dan dikendalikan secara lokal.
2. Sumber daya berbeda dapat mempunyai kebijakan dan
mekanisme berbeda, mencakup Sumber daya komputasi dikelola oleh sistem batch
berbeda, Sistem storage berbeda pada node berbeda, Kebijakan berbeda dipercayakan
kepada user yang sama pada sumber daya berbeda pada Grid.
3. Sifat alami dinamis: Sumber daya dan pengguna dapat
sering berubah
4. Lingkungan kolaboratif bagi e-community (komunitas
elektronik, di internet)
5. Tiga hal yang di-,sharing dalam sebuah sistem grid,
antara lain : Resource, Network dan Proses. Kegunaan / layanan dari sistem grid
sendiri adalah untuk melakukan high throughput computing dibidang penelitian,
ataupun proses komputasi lain yang memerlukan banyak resource komputer.
C. Cara Kerja Grid Computing
Menurut
tulisan singkat oleh Ian Foster ada check-list yang dapat digunakan untuk
mengidentifikasi bahwa suatu sistem melakukan komputasi grid yaitu :
1. Sistem tersebut melakukan koordinasi terhadap
sumberdaya komputasi yang tidak berada dibawah suatu kendali terpusat.
Seandainya sumber daya yang digunakan berada dalam satu cakupan domain
administratif, maka komputasi tersebut belum dapat dikatakan komputasi grid.
2. Sistem tersebut menggunakan standard dan protokol yang
bersifat terbuka (tidak terpaut pada suatu implementasi atau produk tertentu).
Komputasi grid disusun dari kesepakatan-kesepakatan terhadap masalah yang
fundamental, dibutuhkan untuk mewujudkan komputasi bersama dalam skala besar.
Kesepakatan dan standar yang dibutuhkan adalah dalam bidang autentikasi,
otorisasi, pencarian sumberdaya, dan akses terhadap sumber daya.
3. Sistem tersebut berusaha untuk mencapai kualitas
layanan yang canggih, (nontrivial quality of service) yang jauh diatas kualitas
layanan komponen individu dari komputasi grid tersebut.
D. Komponen Grid Computing
Komponen-komponen
grid computing adalah:
· Gram (Grid Resources Allocation & Management)
Komponen
ini dibuat untuk mengatur seluruh sumberdaya komputasi yang tersedia dalam
sebuah sistem komputasi grid. Pengaturan ini termasuk eksekusi program pada
seluruh komputer yang tergabung dalam sistem komputasi grid, mulai dari
inisiasi, monitoring, sampai dengan penjadwalan dan koordinasi antar proses
yang terjadi dalam sistem tersebut. Juga dapat berkoordinasi dengan
sistem-sistem pengaturan sumber daya yang telah ada sebelumnya. Dengan
mekanisme ini program-program yang telah dibuat sebelumnya tidak perlu dibangun
ulang atau bila dimodifikasi, modifikasinya minimum.
· RFT/GridFTP (Reliable File Transfer/Grid File Transfer
Protocol)
Komponen
ini dibuat agar pengguna dapat mengakses data yang berukuran besar dari semua
simpul komputasi yang telah tergabung dalam sebuah sistem komputasi secara
efisien. Hal ini tentu saja berpengaruh karena kinerja komputasi tidak hanya
bergantung pada kecepatan komputer yang tergabung dalam mengeksekusi program,
tapi juga seberapa cepat data yang dibutuhkan dapat diakses. Data yang diakses
juga tidak selalu ada pada komputer yang mengeksekusi.
· MDS (Monitoring and Discovery Services)
Komponen
ini dibuat untuk memonitoring proses komputasi yang sedang dijalankan agar
dapat mendeteksi masalah yang timbul dengan segera. Sedangkan fungsi
disovery dibuat agar pengguna mampu mengetahui keberadaan sumber daya komputasi
beserta karakteristiknya.
· GSI (Grid Security Infrastructure)
Komponen
ini dibuat untuk mengamankan sistem komputasi grid secara keseluruhan. Komponen
ini membedakan teknologi GT4 dengan teknologi-teknologi sebelumnya. Dengan
menerapkan mekanisme keamanan yang tergabung dengan komponen-komponen komputasi
grid lainnya, sistem ini dapat diakses secara luas tanpa sedikitpun mengurangi
tingkat keamanannya. Sistem keamanan ini dibangun dengan segala komponen yang
telah diuji, mencakup proteksi data, autentikasi, delegasi dan autorisasi.
E. Kelemahan Dan Kelebihan Grid Computing
Kelebihan Grid Computing
Beberapa
kelebihan dari grid computing adalah:
· Perkalian dari sumber daya: Resource pool dari CPU dan
storage tersedia ketika idle.
· Lebih cepat dan lebih besar: Komputasi simulasi dan
penyelesaian masalah dapat berjalan lebih cepat dan mencakup domain yang lebih
luas.
· Software dan aplikasi: Pool dari aplikasi dan pustaka
standard, akses terhadap model dan perangkat berbeda, metodologi
penelitian yang lebih baik.
· Data: Akses terhadap sumber data global dan hasil
penelitian lebih baik.
· Ukuran dan kompleksitas dari masalah mengharuskan
orang-orang dalam beberapa organisasi berkolaborasi dan berbagi sumber daya
komputasi, data dan instrumen sehingga terwujud bentuk organisasi baru yaitu
virtual organization.
Kekurangan Grid Computing
Kekurangan
pada grid computing yang lebih ditekankan disini adalah mengenai hambatan yang
dialami oleh masyarakat Indonesia dalam mengaplikasikan teknologi grid
computing. Hambatan-hambatan tersebut adalah sebagai berikut :
· Manajemen institusi yang terlalu birokratis
menyebabkan mereka enggan untuk merelakan fasilitas yang dimiliki untuk
digunakan secara bersama agar mendapatkan manfaat yang lebih besar bagi
masyarakat luas.
· Masih sedikitnya sumber daya manusia yang
kompeten dalam mengelola grid computing.
· Kurangnya pengetahuan yang mencukupi bagi teknisi IT
maupun user non teknisi mengenai manfaat dari grid computing itu sendiri.
Sumber :
I. VIRTUALISASI
Dalam ilmu komputer, virtualisasi (bahasa
Inggris: virtualization) adalah istilah umum yang
mengacu kepada abstraksi dari sumber daya komputer. Definisi lainnya adalah
"sebuah teknik untuk menyembunyikan karakteristik fisik dari sumber daya
komputer dari bagaimana cara sistem lain, aplikasi atau pengguna berinteraksi
dengan sumber daya tersebut. Hal ini termasuk membuat sebuah sumber daya
tunggal (seperti server, sebuah sistem operasi, sebuah aplikasi, atau peralatan
penyimpanan terlihat berfungsi sebagai beberapa sumber daya logikal; atau dapat
juga termasuk definisi untuk membuat beberapa sumber daya fisik (seperti
beberapa peralatan penyimpanan atau server) terlihat sebagai satu sumber daya
logikal."
II. Fungsi Virtualisasi
Secara umum fungsi
virtualisasi data center adalah sebagai berikut.
1. Pengurangan Biaya Investasi Hardware.
2. Kemudahan Backup& Recovery.
3. Kemudahan Deployment.
4. Mengurangi Panas.
5. Mengurangi Biaya Space.
6. Kemudahan Maintenance& Pengelolaan.
7. Standarisasi Hardware.
8. Kemudahan Replacement.
Dalam teknologi virtualisasi sebuah server dipecah
kedalam virtual environment , dan setiap virtual environment dapat diinstall
sistem operasi yang berbeda dari sistem operasi server fisik atau sistem
operasi dari virtual environment lain nya. Ketiaka Virtual environment berjalan
dia tidak tau tentang resource yang digunakan sehingga dalam teknologi
virtualisasi diperlukan sebuah Hypervisor yang mengkoordinasi komunikasi dan
instruksi antara virtual environment dengan resource fisik / psical resource.
Hypervisor inilah yang dipegang oleh administrator dari sebuah server yang
mengimplementasikan teknologi virtualisasi untuk mengatur virtual environment.
Ada 2 jenis Hypervisor dalam
dunia virtualisasi saat ini :
1. Hypervisor Type 1 (Bare Metal Hypervisor)
Dikatakan Bare
Metal hypervisor karena hypervisor ini mengakses langsung hardaware fisik tanpa
bantuan sistem operasi, dan biasnaya untuk menggunakan hypervisor type 1 kita
harus menginstall hypervisor sebagai sistem operasi (Bukan diinstall dalam
sistem operasi).
Contoh Hypervisor Type 1 diantaranya : KVM , Red hat Enterprise Virtualisation
(RHEV),XEN/Citrix XenServer,Hyper-V,VMware vSphere/ESXi
2. Hypervisor Type 2 (Hosted Hypervisor
Jenis Hypervisor ini
memerlukan sistem operasi untuk berjalan, karena jenis hyper visor ini berjalan
diatas sistem operasi.
Contoh Hypervisor Type 2 diantaranya : VMware Work station , VMware Player ,Virtual Box
III. Jenis dan Tipe Virtualisasi
Pembagian berikut
ini berdasarkan hasil akhir dari penerapan teknologi virtualisasi,
walau dalam prakteknya akan sangat komplek dan hampir mirip dalam
konfigurasi.Untuk saat ini implementasi virtualisasi dalam dunia komputer
dapat dikategorikan sebagai berikut :
1. Virtualisasi Server
Virtualisasi Server adalah penggunaan teknologi
virtualisasi dengan tujuan untuk memecah resource fisik server kedalam beberapa
Virtual server yang nantinya akan diinstall berbagai macam sistem operasi
sesuai kebutuhan atau bisa juga virtual server ini dijual /disewakan oleh pihak
hosting, kita sering mendengarnya dengan istilah VPS (Virtual Private Server).
2. Virtualisasi Desktop
Virtualisasi desktop merupakan
teknologi software yang memisahkan desktop environment dan aplikasi desktop
yang terinstall dengan resource fisik ketika desktop diakses oleh user.
Virtualisasi desktop biasanya digunakan bebarengan dengan virtualisasi aplikasi
dan user provile management systems atau sekarang lebih dikenal dengan
“Virtualisasi User” dimana dalam 1 komputer bisa diakses oleh ratusan user
dalam 1 waktu tanpa mengganggu user lain nya. Virtualisasi user atau desktop
bisa diakses menggunakan remote desktop atau menggunakan cloud interface
/browser sehingga lebih flexible.
3. Virtualisasi Aplikasi
Virtualisasi aplikasi
memungkinkan kita untuk menjalankan sebuah aplikasi tanpa harus menginstall
aplikasi tersebut bahkan bisa menjalankan nya secara remote dengan menggunakan
web interface atau cloud interface. Pada dasarnya aplikasi akan dibungkus kedalam
sebuah runtime environment (seperti virtual machine) dan ketika aplikasi
dijalankan aplikasi tersebut berjalan diatas virtual environment yang telah di
bundle bersamanya yang menjadikan aplikasi menjadi portable. Virtual
environment akan berjalan diatas sistem operasi dan aplikasi berjalan diatas
virtual environment sehingga aplikasi benar-benar terisolasi dari OS fisik.
Ada beberapa
pilihan/metode akses user ke virtual aplikasi antara lain :
· User mengakses virtual aplikasi yang telah
diintegrasikan dengan webserver melelui web browser atau cloud interface
(streaming)
· User mengkopi aplikasi yang sudah dibundle dengan
runtime environment (yang menjadikan aplikasi ini portable tanpa perlu install)
dan mengekseskusinya langsung di mesin yang dia miliki/pakai tanpa install dan
setting apapun
Ada beberapa produk yang digunakan untuk membuat Virtualisasi aplikasi antara
lain : Microsoft App-V, VMware Thinapp,Symantec Workspace Virtualization,Spoon,Cameyo
- Virtualisasi Network
Virtualisasi network merupakan proses penggabungan
network hardware dan software kedalam satu virtual unit(Network Server) yang
menyediakan container yang berfungsi seperti halnya perangkat network fisik.
virtualisasi network biasanya digunakan oleh developer untuk mengetest sistem
dan aplikasi yang sedang dikembangkannya.
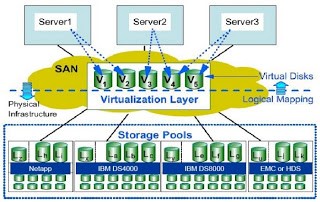
- Virtualisasi Storage
Virtualisasi storage menyediakan media penyimpan
(storage) yang terisolasi (terpisah dari resource fisik),aman dan mudah dalam
fail over dan backup. salah satu contoh implementasi virtualisasi storage yang
gampang kita lihat adalah fasilitas cloud storage seperti DropBox dan Google
drive yang menyediakan /menyewakan cloud storage bagi pelanggannya dengan
menawarkan flexibilitas dimana user bisa mengakses storage kapanpun dan
dimanapun.
Sumber:
MapReduce dan NoSQL (Not Only SQL)
A. MAPREDUCE
MapReduce adalah model pemrograman rilisan
Google yang ditujukan untuk memproses data berukuran raksasa secara
terdistribusi dan paralel dalam cluster yang terdiri atas ribuan komputer.
Dalam memproses data, secara garis besar MapReduce dapat dibagi dalam dua
proses yaitu proses Map dan proses Reduce. Kedua jenis proses ini
didistribusikan atau dibagi-bagikan ke setiap komputer dalam suatu cluster
(kelompok komputer yang salih terhubung) dan berjalan secara paralel tanpa
saling bergantung satu dengan yang lainnya. Proses Map bertugas untuk
mengumpulkan informasi dari potongan-potongan data yang terdistribusi dalam
tiap komputer dalam cluster. Hasilnya diserahkan kepada proses Reduce untuk
diproses lebih lanjut. Hasil proses Reduce merupakan hasil akhir yang dikirim
ke pengguna. Untuk menggunakan MapReduce, seorang programer cukup membuat dua
program yaitu program yang memuat kalkulasi atau prosedur yang akan dilakukan
oleh proses Map dan Reduce. Jadi tidak perlu pusing memikirkan bagaimana
memotong-motong data untuk dibagi-bagikan kepada tiap komputer, dan
memprosesnya secara paralel kemudian mengumpulkannya kembali. Semua proses ini
akan dikerjakan secara otomatis oleh MapReduce yang dijalankan diatas Google
File System.
Tujuan
MapReduce adalah model pemrograman rilisan
Google yang ditujukan untuk memproses data berukuran raksasa secara
terdistribusi dan paralel dalam cluster yang terdiri atas ribuan komputer.
Dalam memproses data, secara garis besar MapReduce dapat dibagi dalam dua
proses yaitu proses Map dan proses Reduce.
Tahapan proses MapReduce
MapReduce memiliki dua tahap dalam
memproses data yaitu map danreduce. Tahap pertama
dari MapReduce disebut map.
· Map melakukan
transformasi setiap data elemen input menjadi data elemen output. Map dapat
dicontohkan dengan suatu fungsi toUpper(str) yang akan mengubah setiap huruf
kecil (lowercase) menjadi huruf besar (uppercase). Setiap data
elemen huruf kecil (lowercase) yang menjadi input dari fungsi ini akan
ditransformasi menjadi data output elemen yang berupa huruf besar (uppercase). Map memiliki
fungsi yang dipanggil untuk setiap input yang menghasilkan output pasangan intermediate <key, value>.
· Reduce adalah
tahap yang dilakukan setelah mapping selesai. Reduce akan
memeriksa semua value input dan mengelompokkannya menjadi
satu value output. Reduce menghasilkan output pasangan intermediate .
Sebelum memasuki tahap reduce, pasangan intermediate <key, value>
dikelompokkan berdasarkan key, tahap ini dinamakan tahap shuffle.
B. NoSQL (Not Only SQL)
NoSQL adalah istilah untuk menyatakan
berbagai hal yang didalamnya termasuk database sederhana yang
berisikan key dan value seperti Memcache, ataupun yang lebih
canggih yaitu non-database relational seperti MongoDB, Cassandra, CouchDB, dan
yang lainnya.
Wikipedia menyatakan
NoSQL adalah sistem menejemen database yang berbeda dari sistem
menejemen database relasional yang klasik dalam beberapa hal. NoSQL mungkin
tidak membutuhkan skema table dan umumnya menghindari operasi join dan
berkembang secara horisontal. Akademisi menyebut database seperti ini
sebagai structured storage, istilah yang didalamnya mencakup sistem
menejemen database relasional.
Kesimpulan
Map Reduce danNoSQL (Not Only SQL) adalah
sebuah pemogramaan framework guna untuk membantu user mengembangankan sebuah
data yang ukuran besar dapat terdistribusi satu sama lain. Map-Reduce adalah
salah satu konsep teknis yang sangat penting di dalam teknologi cloud terutama
karena dapat diterapkannya dalam lingkungan distributed computing. Dengan
demikian akan menjamin skalabilitas aplikasi kita.
Salah satu contoh penerapan nyata
map-reduce ini dalam suatu produk adalah yang dilakukan Google. Dengan inspirasi
dari functional programming map dan reduce Google bisa menghasilkan
filesystem distributed yang sangat scalable, Google Big
Table. Dan juga terinspirasi dari Google, pada ranah open source terlihat
percepatan pengembangan framework lainnya yang juga bersifat terdistribusi dan
menggunakan konsep yang sama, project open source tersebut bernama Apache
Hadoop.
NoSQL Database
A. Pengertian No Sql
Berbeda dengan SQL Database, dari namanya
saja sudah bisa ditebak bahwa nosql database adalah kebalikan dari sql
database. Tidak relational / tanpa relation. Database nosql atau yang biasa
disebut NoSQL database / cloud database merupakan penyimpanan data / database
yang tidak terstruktur.
Nosql database tidak seperti sql database
yang menggunakan tabel dalam penyusunan datanya, nosql database menggabungkan
semua database tidak membedakan jenis2nya dan tanpa karakteristik umum. Tapi
nosql database ini memiliki kecepatan yang super cepat dibanding dengan sql
database, pencariannya lebih terfokus. Nosql sebetulnya tidak 100% menyimpan
data dengan cara tidak terstruktur, terkadang ada miripnya dengan sql database
dengan sedikit susunan pada saat2 tertentu.
Bedanya nosql database ini menyusun bagian
didalam bagian lainnya (subset). Jadi setiap bagian akan memiliki beberapa
bagian lagi didalamnya. Nosql ini cocok dan biasa digunakan untuk penyimpanan
aplikasi atau data yang sangat besar. Karena dengan menggunakan nosql data
dapat diakses dengan sangat fleksibel dan sangat sedikit kemungkinan error
ketika mengakses banyak data dengan format yang berbeda-beda.
B. Karakteristik NoSql
1. NoSQL tidak menggunakan model data
relasional dengan demikian tidak menggunakan bahasa SQL .
2. NoSQL toko volume data yang besar .
3. Dalam lingkungan terdistribusi (data
menyebar ke mesin yang berbeda ) , kita menggunakan NoSQL tanpa ketidaksesuaian
.
4. Jika ada kesalahan atau kegagalan ada di
setiap mesin , maka dalam hal ini tidak akan ada penghentian pekerjaan .
5. NoSQL adalah database open source, yaitu
kode sumbernya tersedia untuk semua orang dan bebas menggunakannya tanpa overhead
.
6. Memungkinkan data NoSQL untuk menyimpan
dalam catatan yang tidak memiliki apapun skema tetap.
7. NoSQL tidak menggunakan konsep ACID
properti .
8. NoSQL adalah horizontal scalable
menyebabkan kinerja tinggi dalam cara linear .
9. Hal ini memiliki struktur yang lebih
fleksibel..
C. Pengelompokan NoSQL ( Jenis Penyimpanan
Data )
1 . Key value databases
Key
value databases nama itu sendiri menyatakan bahwa itu adalah kombinasi dari dua
hal yang merupakan kunci dan nilai . Ini adalah salah satu low profile sistem
database ( tradisional) . Key Value database ( KV ) adalah ibu dari semua
database NoSQL .
- Key
adalah sebuah identifikasi unik untuk entri data tertentu. Kunci tidak harus
diulang jika digunakan.
- Value adalah jenis data yang ditunjuk oleh
kunci.
Contohnya:
Dynamo, Riak, Redis, MemcacheDB, Project Voldemort
2 . Document Stores Databases
Document
Stores Databases adalah mereka database NoSQL yang menggunakan catatan sebagai
dokumen. Jenis Document Stores Databases terstruktur (teks ) atau semi -
terstruktur ( XML ) dokumen yang biasanya hirarki di nature . Di sini setiap
dokumen terdiri
Dari
satu set kunci dan nilai-nilai yang hampir sama seperti ada dalam database Key
Value . Setiap database yang berada di Document Stores Databases dipindahkan ke
field dengan menggunakan pointer dengan menggunakan teknik hashing . Document
Stores Databases adalah skema bebas dan tidak tetap di nature . Struktur
Document Stores Databases digambarkan pada Gambar di bawah ini
Contohnya: MarkLogic, MongoDB, Couchbase
3 . Columnar Database
Columnar
Database juga dikenal sebagai database keluarga kolom karena mereka adalah
database berorientasi kolom . Contohnya: HBase, Accumulo, Cassandra
Ada dua
jenis database berorientasi kolom yang detail seperti yang diberikan di bawah
ini :
( 1 )
Wide-Column data stores:
Ini
adalah salah satu jenis database NoSQL . Menyimpan data Kolom lebar adalah
mereka database yang digunakan untuk pengolahan web ,streaming data dan dokumen
.
( 2 )
Column oriented databases:
Untuk
memahami database berorientasi kolom mari kita mengambil contoh database bank
yang diberikan dalam gambar 9 yang bidang atribut adalah EmpID , Gaji dan
penunjukan dan nilai-nilai sesuai dengan itu adalah seperti yang digambarkan
dalam database .
4 . Graph databases.
Database
Grafik didasarkan pada teori graf . Secara umum, kita melihat grafik yang
biasanya terdiri dari node \ , sifat dan tepi .
Database
NoSQL Grafik terdiri dari :
( 1 )
Node mewakili entitas
( 2 )
Properti merupakan atribut
( 3 )
Tepi mewakili hubungan
D. Peranan Data dan Arsitektur di NoSql
Ada empat komponen dalam blok bangunan
nya. :
1. Modelling Language: Ini menggambarkan
struktur database dan juga mendefinisikan skema yang itu didasarkan. data
adalahyang disimpan dalam bentuk baris dan kolom menggunakan XML format. Dan
setiap data (nilai) sesuai dengan itu ditugaskan kunci yang unik. Untuk akses
data lebih cepat, model dibangun di lingkungan yang sesuai.
2. Database Struktur: Setiap basis data
sementara bangunan menggunakan struktur data sendiri, dan menyimpan data
menggunakan perangkat penyimpanan permanen.
3. Database bahasa Query: Semua operasi yang
dilakukan pada database yang membuat, merubah, membaca dan menghapus.
4. Transaksi: Dalam setiap transaksi dalam
data, mungkin ada jenis kesalahan atau kegagalan, kemudian, mesin tidak akan
berhenti kerja.
E. Kelebihan NoSQL di banding Relasional
Database
1. NoSQL bisa menampung data yang
terstruktur, semi terstruktur dan tidak terstuktur secara efesien dalam skala
besar (big data/cloud).
2. Menggunakan OOP dalam pengaksesan atau
manipulasi datanya.
3. NoSQL tidak mengenal schema tabel yang
kaku dengan format data yang kaku. NoSQL sangat cocok untuk data yang tidak
terstruktur, istilah singkat untuk fitur ini adalah Dynamic Schema.
4. Autosharding, istilah sederhananya, jika
database noSQL di jalankandi cluster server (multiple server) maka data akan
tersebar secara otomatis dan merata keseluruh server.
F. Kekurangan dari database NoSQL
1. Hostingnya mahal, beberapa layanan di luar
negeri mencharge biaya 100-200USD untuk hosting database noSQL. Selain itu,
saya belum pernah menemukan hosting Cpanel yang mendukung database MongoDB atau
database noSQL lainnya.
2. Perlu waktu untuk belajar. Contohnya
ketika anda pindah dari MongoDB ke Cassandra, maka anda harus belajar lagi dari
awal, berbeda dengan database RDMS.
G. Contoh-contoh Aplikasi NoSQL Database
1. MongoDB
Merupakan basis data yang paling populer diantara
basis data NoSQL lainnya. Hal ini dikarenakan pemasangan maupun penggunaan
mongoDB tidaklah sulit atau merepotkan penggunanya. Selain itu mongoDB juga
merupakan salah satu basis data yang open source sehingga pengembangan mongoDB
sendiri cukup pesat karena setiap orang bisa berpartisipasi untuk
mengembangkannya.
2. CouchDB
Apache CouchDB, biasa disebut dengan CouchDB saja,
merupakan basis data NoSQL yang dikembangkan oleh Apache. CouchDB lebih dulu
muncul jauh sebelum mongoDB yaitu pada tahun 2005. CouchDB tidak menyimpan
datanya dalam tabel melainkan dalam dokumen seperti halnya mongoDB.
3. Cassandra
Cassandra merupakan sebuah sistem penyimpanan data
terdistribusi untuk menangani jumlah data yang sangat besar dan terstruktur.
Cassandra juga dikembangkan Apache, pengembang yang sama untuk basis data
CouchDB.
4. Redis
Lagi-lagi basis data open source, redis merupakan
basis data berbasis key-value paling populer menurut situs DB-Engines.com.
Redis merupakan singkatan dari REmote DIctionary Server. Basis data ini
dikembangkan oleh Salvatore Sanfilippo pada tahun 2009 dan ditulis dalam bahasa
C. Redis banyak dipilih karena memiliki fitur in-memory, networked, dan
durabilitas tinggi.
5. Riak
Riak merupakan basis data NoSQL terdistribusi yang
menyimpan datanya dalam bentu key-value. Riak menawarkan fitur high
availability, fault tolerance, operational simplicaity, dan scalability. Riak
memiliki dua versi yakni Open source edition dan Enterprise edition. Enterprise
edition menawarkan dukungan berbayar intensif dari pengembangnya. Pengguna Open
source edition dapat bermigrasi kapan saja ke Enterprise edition jika
dibutuhkan.
6. Neo4J
Neo4j merupakan basis data NoSQL dengan sistem graf.
Apabila berurusan dengan basis data berbasis graf, maka Neo4j lah yang paling
dikenal. Neo4j menyimpan relasi antar objek dalam struktur seperti graf, dimana
setiap objek merujuk ke objek lainnya secara langsung.
7. OrientDB
OrientDB merupakan basis data graf terdistribusi
generasi kedua. Basis data ini dibuat dalam bahasa Java oleh Orient
Technologies LTD dan dirilis pertama kali tahun 2010. OrientDB diklaim sangat
cepat dan mampu menyimpan 220.000 record per detik diperangkat standar.